Framework
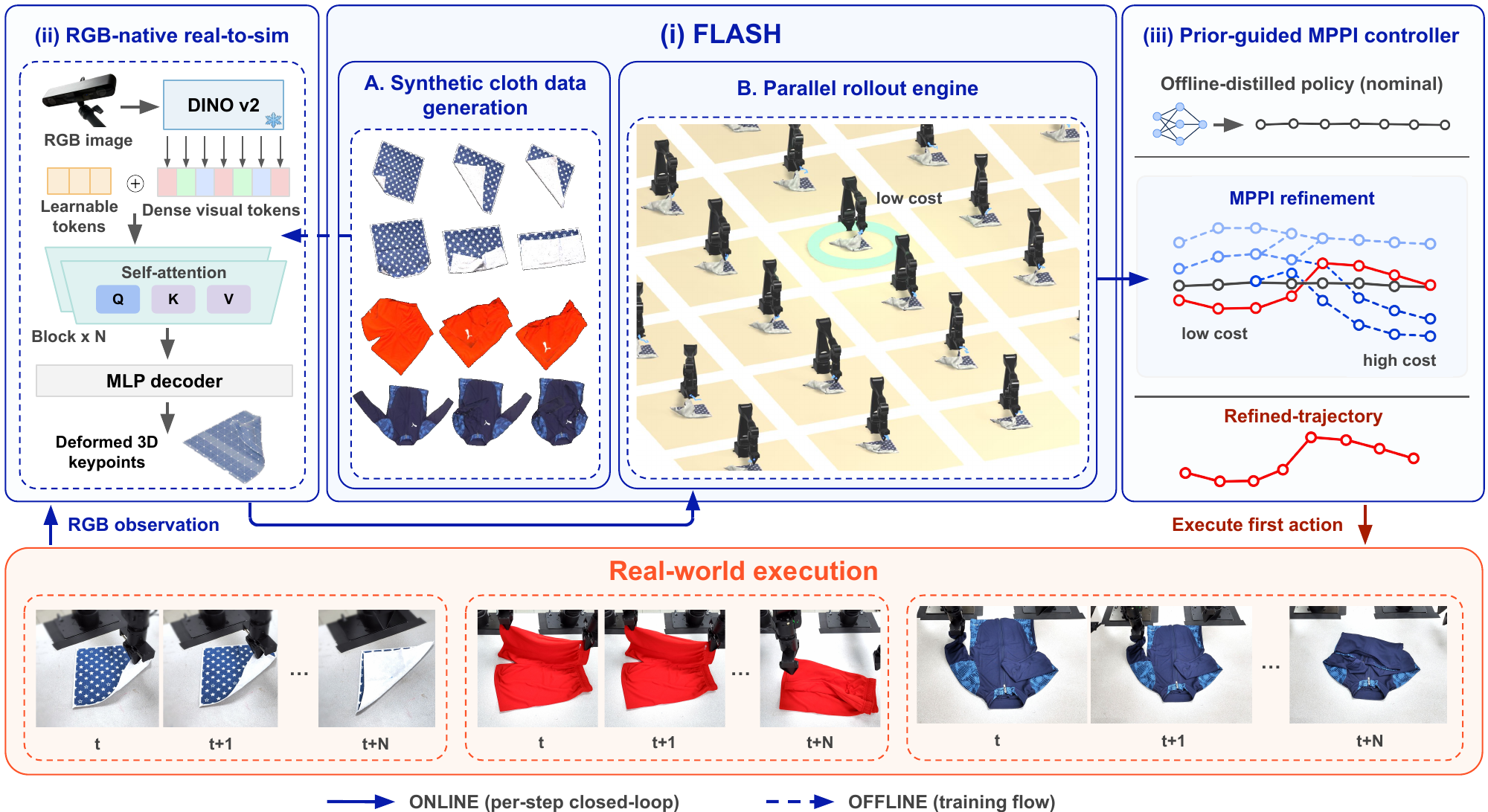
Overview of the proposed framework. Offline, we use FLASH to generate synthetic data for real-to-sim training. Online, RGB observations initialize physics rollouts that refine the prior policy through MPPI for closed-loop hardware execution.


